
网络爬虫是以一定的规则自动抓取互联网信息的程序或者脚本,需要面向不同的应用场合解决网络连接、爬取策略等问题。Scrapy 爬虫框架可以帮助开发者快速开发爬虫,其基于Twisted异步网络库来处理网络通讯,能够实现并行、分布式爬取,提高了爬取效率。Scrapy 爬虫框架的结构如图1 所示,包括以下5 个主要模块:
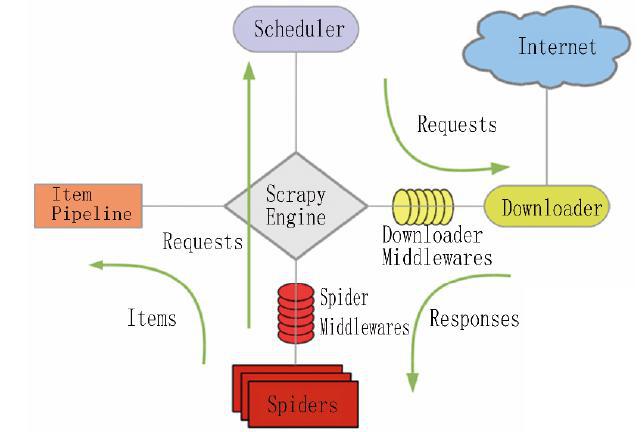
①Scrapy Engine: 引擎,负责Spiders( 爬虫) 、Item Pipeline( 队列) 、Downloader( 下载器) 、Scheduler(调度器) 之间的信息通讯和数据传递;
②Scheduler: 调度器,负责接受引擎发送过来的Requests( 请求) ,并按照一定的规则放入队列中;
③Downloader: 下载器,负责下载Scrapy Engine发送的所有Requests,并将其获取到的Responses(响应) 交还给Scrapy Engine,由引擎交给Spiders 来处理;
④Spiders: 负责处理所有Responses,从中提取数据,获取Item 字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler;
⑤Item Pipeline: 负责处理Spiders 中获取到的Item,并进行处理,如去重、持久化存储等。
Scrapy 的工作流程是: Scrapy Engine 启动并控制爬虫运行,首先由Spider 根据编写的爬虫策略控制Scrapy Engine 向Scheduler 发送请求(Requests) ,Scheduler 将请求加入队列,依次向Downloader发送,Downloader 接收请求后将互联网信息下载到本地成为响应(Response) ,传递给Spiders处理后形成Items,由Pipeline 保存或输出。
文献参考:
评论列表 ( 0 )